
在2020年十月的一場Search On活動中,Google提到在搜尋上他們有了一個重大的突破,稱之為「片段資訊檢索(Passage Retrieval)」,在全面推出後將影響7%左右的搜尋結果。這個改動是什麼? 和以往的系統有何差異? 這篇文章會來慢慢探討。
摘要
- 隨著「片段資訊檢索 」的啟用,Google將會把網頁中片段資訊與搜尋字的相關性納入排名考量,而不再只是網頁整體與搜尋字的相關性。
- 這項更新會在2020年年底前推出,從美國的英文搜尋開始,將逐步拓展到全球每個語言。
- 推出後預計將影響7%的搜尋結果,可謂相當顯著。(做為比較基準,2019年啟用的BERT,號稱五年來最大的進步,推出時影響了約10%的英文搜尋結果。)
- 這次變動不影響Google收錄網站的方式,可以視作排名上的變動。
片段檢索 vs 文件檢索
以往Google是採取文件檢索(Document Retrieval)的方式,會從資料庫中找出與搜尋字相關性最高的網頁*並回傳到搜尋結果上;但在改為片段檢索(Passage Retrieval)後,Google將會回傳與搜尋字相關性最高的訊息片段。
訊息片段(Passage)指的是網頁上的某段訊息,也就是說,若一個訊息片段與搜尋字有超高度相關性,但該片段所在的頁面與搜尋字只有低度相關性,在這次改動之後,這種頁面的排名將有機會提高。
嚴格來說,文件(document)和網頁(page)是不一樣的東西,但為了簡化討論與方便理解,這邊視為一樣的東西,如有興趣閱讀更多可以參考這篇。
這項改動解決了什麼問題
在機器學習的領域中,判斷一個東西是否「相關」有兩個非常重要的指標: Precision和Recall。Precision代表選出來的結果裡面,有多少比例是有相關的;而Recall指的是,全部有相關的東西中,有多少比例被選了出來。

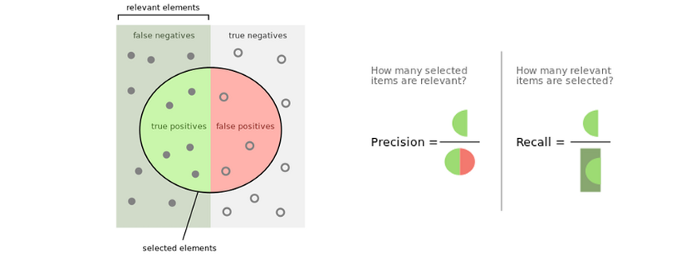
有了這個觀念,就能理解在文件檢索的情形下,很多網頁會很難在SEO上有排名,因為對一個搜尋字來說真正相關的資訊(上圖綠色半圓部分),會因為與太多無用資訊(上圖紅色半圓部分)放在同一頁(整個圓圈區域),導致precision score非常低,稀釋了其相關性。而在片段資訊檢索下,Google對recall的重視程度會大於precision,網頁上有太多雜訊沒關係,更重要的是相關資訊的部分夠不夠完整。
白話文一句: Google能更容易對使用者輸入的問題給出更相關的答案。
現實中也不乏類似的例子,問一個非常細節的問題,有人會把該領域的相關基本資訊都講一遍,但卻沒有回答真正的問題;有人雖然知道答案,但卻先扯個天南地北再給出答案。
舉例
你可能會問「為什麼會有網頁要把有用資訊放在一堆無用資訊中?」 要記得,資訊有沒有用是根據搜尋字來決定的,有可能使用者輸入的搜尋字非常非常具體(specific),讓真正的相關資訊本身就非常匱乏,也有可能因為網頁本身的形式屬於新聞整理或論壇的類型,讓同個頁面上有多主題或者過多雜訊。
搜尋字: 「怎麼知道我家玻璃有沒有抗UV?」
Google在Search On上給的例子是 「怎麼知道我家玻璃有沒有抗UV?」這個搜尋字,原本的第一名(下圖A)是篇講抗UV玻璃的文章,文章中討論不同的紫外線波長、不同種類玻璃哪個最有效、實驗結果…等等,內容相當專業但卻沒有明確回答到搜尋者的問題。
而在Passage-Based Retrieval後的第一名(下圖B)是篇論壇文章,從右邊的滾輪可以看到整個網頁相當長,但僅有中間的黃色一小段精準的回答到了搜尋的問題(高度相關),該頁討論串的下方有點歪題甚至變成鄉民在爭論。
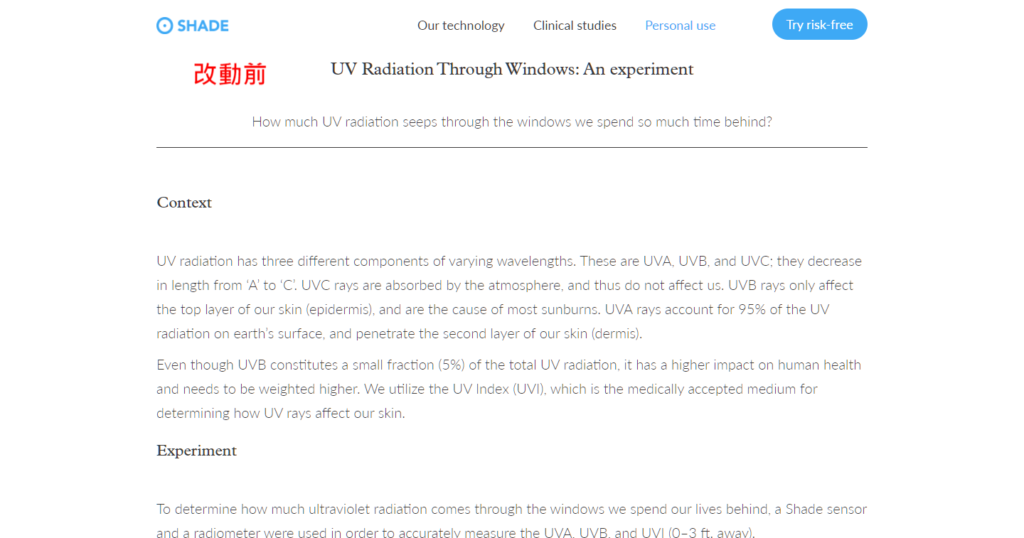
圖A: 文章專業地討論抗UV玻璃,但並未滿足搜尋者意圖 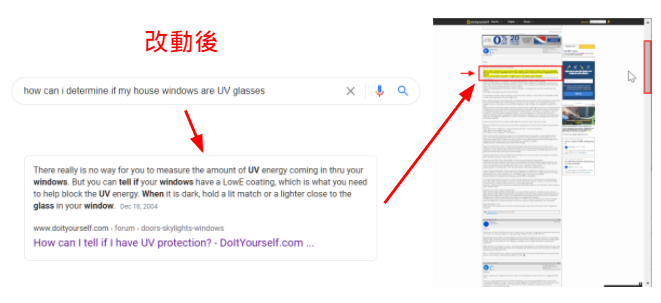
圖B: 網頁上有非常多的不相關內容,但Google找出最符合搜尋意圖的片段


這並不影響Google索引(Indexing)系統的方式
在Search On的影片中,講者說”We are not just able to index webpages, but individual passages from those pages“,這段話讓很多SEO們感到困惑,認為Google改變了其索引的方式,不再收錄網頁,而是收錄「片段」,但這項理解是錯誤的,Google仍然索引整個網頁,只是在排名階段,會將片段資訊的相關性納入考量。

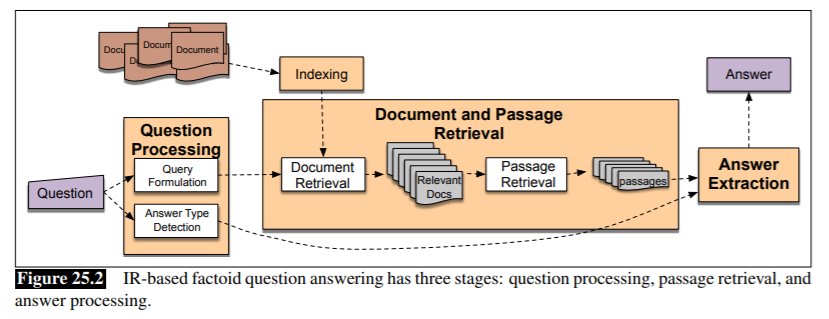
下圖是自然語言(NLP)中,在處理事實性問答(factoid question-answering)的三個階段,在第二步可以看到,系統會在Document Retrival選出相關檔案後,再進行Passage Retrieval的動作將重點片段提取出來。

(註1.) 我認為講者並非講錯,而是SEO普遍認知的”Index”可能和工程師的”Index”有所差異,搜尋一下passage indexing亦能找到相當多學術論文在討論,但避免歧異,這篇文章用「片段資訊檢索(Passage Retrieval)」稱呼之。
(註2.) 雖然中文都用「檢索」,但片段資訊檢索(retrieval),是Google為搜尋字找出相關內容的過程;而搜尋引擎抓取網站的檢索(crawling),指的是Google派出爬蟲到網頁上把內容抓回來的過程。
小結
在BERT推出後,看到SEO領域中很多人在討論怎麼將網站對BERT進行優化;這次的更新,不免俗地可以預期將會開始討論SEO該採取甚麼措施來優化片段資訊檢索。
這篇文章的目的是做個介紹與解釋,一來為SEO領域的新聞做個介紹,二來讓大家將來在看到相關SEO資訊的時候有更好的判斷力。未來若聽到他人說「Google現在改為片段檢索,所以網站要怎樣怎樣才會對SEO好」,試著問自己「真的是這樣嗎?」,「不管有沒有這次更新,難道文章不是本來就該進行這些優化嗎?」
這次的片段資訊檢索介紹到這邊,如果有不清楚的地方或對這次更新有什麼想法,歡迎留言讓我知道!
片段資訊檢索(Passage Retrieval) 的做法固然不錯,但很容易將它與Featured Snippets 混淆在一起,看似有關連,又是個排名訊號,特別是在Google 又跳出來澄清 “Google confirms it doesn’t index passages separately ”
https://searchengineland.com/google-confirms-it-doesnt-index-passages-separately-342387
不知道版大您的看法呢?
Passages跟Featured Snippets的確很相似,但Danny解釋是兩者由不同機制所產生,這篇文章有很好的整理! Indexing和ranking是兩個不同的階段,看起來FS和passage都屬於在做排序時發生的事情,關於google澄清passage屬於ranking階段可以看文章中倒數第二段~
謝謝大大文章分享,解答了我的疑惑 🙂
這邊 Martin Splitt 有說明 Featured Snippet and Passages Ranking.
https://www.searchenginejournal.com/google-passage-ranking-martin-splitt/388206
非常感謝補充! 和Danny講的一樣,Passage Ranking和Featured Snippet屬於兩個不同的機制,但影片中Martin有講到一個很重要的點說「Passage Ranking一般是被應用在普通搜尋結果(10 blue links)的排序上」。
讀完這篇文章的朋友們,如果還有問題可以到Search Engine Journal的文章中找答案!