
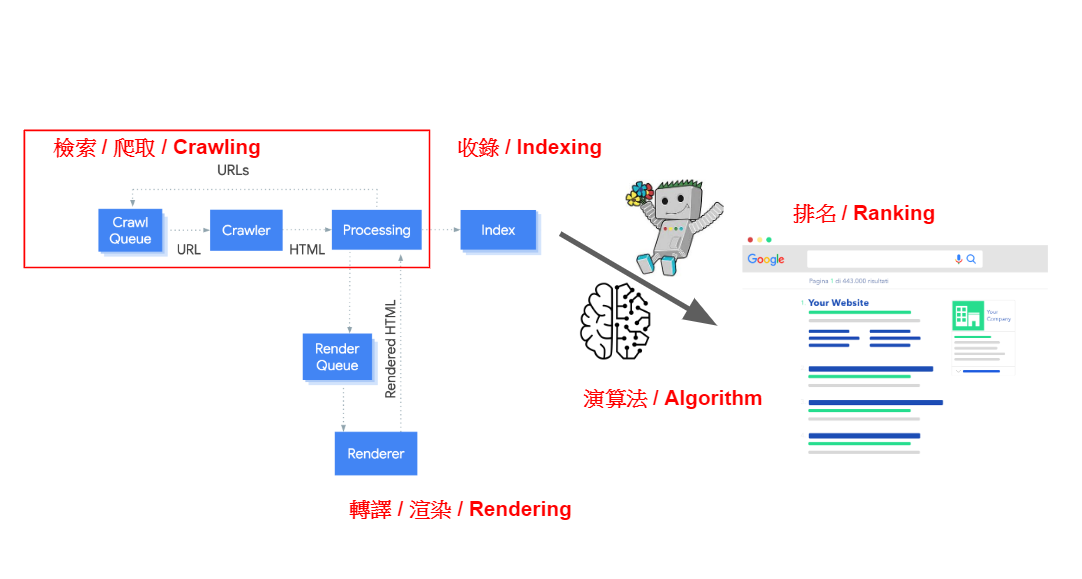
檢索或抓取(Crawl)是讓網站出現在Google排名的第一步,這個過程的概念其實並不複雜,Google有了一個網址(URL),去拜訪這個網頁,然後從網頁上的內容上發現更多的網址,加進檢索序列中,如此循環下去。
這個過程看似簡單,但是網路世界卻很複雜… (不然也不會寫了這麼多😂)
本文目錄
這篇文章有點長,但耐心看完一定會有所收穫的,Enjoy!
- 前言
- 為什麼要了解抓取的概念
- 一切都要從網址開始說起
- 檢索過程的三個階段
- SEO在檢索階段能優化些什麼
- 如何防止搜尋引擎爬取?
- 如何檢測搜尋引擎有無檢索問題
- 因為「檢索」沒有設定好而出現的悲劇案例
- 搜尋引擎爬取的常見問題
- 結語
前言
最近我在公司講了一場SEO內訓,主題是《Before Google Ranks a Page: The Lifecycle of Googlebot》,探討網頁在有資格出現在搜尋結果前的三個必要階段「抓(爬)取」、「轉譯」、「收錄」。過沒多久就讀到Harris先生的文章《SEO基礎觀念:認識檢索 (Crawl) 與索引 ( Index )》,啟發了我寫這篇文章的動力,希望能幫助充實中文的SEO內容。這個系列會把這個觀念分成三篇文章,讓大家對技術面的SEO有更進一步的認識。
為什麼要了解抓取的概念
因為「抓取」是讓網頁出現在搜尋結果的必要第一步,Google如果連網頁的存在都不知道,那更別提能在搜尋結果上有排名。經營一個網站,我們希望Google爬我們想被找到的網頁,也希望Google不要爬我們不想被看到的網頁。另外,隨著網站的發展,外掛插件的安裝和移除,常常會讓網站留下一些”技術債”。而SEO在這裡的工作就是要讓Google能夠用最有效率的方式抓取網站。

聽不懂啦,換個方式說說看!
把整個網路世界想像成一個超巨大圖書館,每個網頁都是一本書,然後搜尋引擎是圖書館管理員 (其中Google是最聰明的那個),看過的書都會記在腦海裡,只要有人來問他問題,就會根據自己的印象告訴對方可以去參考哪些書。而「抓取」就是管理員來看你的「書」的過程,管理員沒看過你的書,就算寫得再好也不會被推薦。
網站怎麼會有不想被Google看到的網頁? 舉個例來聽聽!
例如正在開發中的網站,或專門讓工程師測試新功能的「鏡像」網站,一般就不會想要被搜尋引擎看到。
一切都要從網址開始說起
網址(URLs)是網頁的地址,像https://www.darrenhuang.com/about-darren-huang就是個網址。這裡要給大家一個測驗,沒答對的話答應我你會把這篇看完!
下面六個網址,那些在搜尋引擎的眼中和上面的網址是一樣的,那些是不一樣的?
A) https://www.darrenhuang.com/about-darren-huang/ (結尾多了斜線) B) http://www.darrenhuang.com/about-darren-huang (開頭為http而非https) C) https://www.darrenhuang.com/ABOUT-DARREN-HUANG (大寫) D) https://darrenhuang.com/about-darren-huang (少了www) E) https://www.darrenhuang.com/about-darren-huang?utm_source=facebook (後面多了追蹤參數) F) https://www.darrenhuang.com/about-darren-huang.html (後面多了.html的檔名)
自己思考一下,再來看答案!
答案是: 以上皆非。沒錯,上面的幾種情況,技術上都屬於不同網址。儘管不常見,但各自「有可能」代表不同的頁面,因此在爬取階段,這七個網址都會被搜尋引擎當作獨立網址對待。
檢索過程的三個階段
檢索是Google收錄網頁三步驟的第一大步,而這一大步又可分成三個階段「加入檢索隊列(Crawl Queue)」、「爬蟲拜訪(Crawler)」、「頁面處理(Processing)」 ,下面依序作介紹。
Step 1: 加入檢索隊列(Crawl Queue)

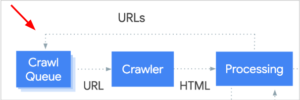
搜尋引擎會將其找到的網址,都放進隊列(crawl queue)中,在隊列裡的網址就會有搜尋引擎的”爬蟲”來拜訪。而搜尋引擎主要靠下面三種方法發現新的網址:
1. 連結
包含內部連結和外部連結,爬蟲能透過一個頁面上的連結發現新的網址,並加進檢索隊列中。
2. 站點地圖(Sitemap)
相較於透過連結一個個找出新網址再加進隊列的方式,站點地圖能夠一次讓爬蟲知道網站上有那些網址,是個較有效率的方法。
3. 站長工具
大型的搜尋引擎(Google, Bing…etc)都有出自己的站長工具,讓網站管理員可以提交網址或是站點地圖,這個舉動相當於直接通知Google說:「欸! 我這邊有個一個(一堆)網址,把它(們)加進檢索隊列喔!」。
SEO意涵: 網站要有排名就要先被檢索,要被檢索就要先讓Google知道你的存在然後排進檢索隊列。
Step 2: 爬蟲拜訪(Crawler)
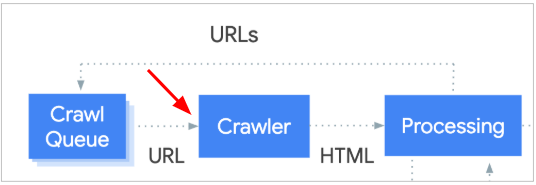
在搜尋引擎知道網址的存在後,就會派出”爬蟲”去這個網址看看,然後把網頁內容抓回來。要注意,爬蟲在這之前,只知道有這個地址的存在,至於地址上有什麼東西他們並沒有太多的資訊。
這是一個爬蟲(搜尋引擎)和伺服器(你的網站)溝通的過程,首先爬蟲會發出一個請求:「嘿,我有一個網址,可以讓我看看上面有什麼嗎?」,然後會遇到的下面幾種情況:
狀況A: 伺服器: 來,給你 (代碼: 2XX)
爬蟲得到它要的東西,進行下一步。
狀況B: 伺服器: 你這個網址是舊的,來,你去另外一個網址看看 (代碼: 3XX)
爬蟲被引導到另一個網址,再進行一樣的步驟,這就是所謂的轉址或重定向(redirect)。
狀況C: 伺服器: 不給! 你這個網址有問題! (代碼: 4XX)
爬蟲沒有得到它要的東西,因為網址是錯的,錯誤原因可能是伺服器根本沒有這個檔案,或者伺服器認定爬蟲沒有權限要求這個頁面。
狀況D: 伺服器: *&#@!$ 抱歉現在給不了,我這邊出了點錯 (代碼: 5XX)
爬蟲沒有得到它要的東西,但這次是伺服器的問題,網址可能沒有錯。遇到這個情形爬蟲會把網址加回檢索序列(step 1)中,晚點再回來爬看看。
狀況E: ….. (伺服器根本沒聽到爬蟲的請求,沒回應) (代碼: 無)
這個情況下爬蟲發出的請求因為某種原因(例如: 防火牆)沒有送到伺服器那邊,所以沒收到回應,連網址上到底有沒有東西都不知道。
SEO意涵: 上面幾種情況中最有問題的是D,它代表網址所在的伺服器不穩定,用戶或爬蟲來到這個網址看到了伺服器錯誤的訊息。另外四種情況並沒有絕對的好壞。沒錯,A不代表一定沒有問題,B, C, E也不是一定有問題,下面會再多做解釋。
括號內的代碼是什麼意思?
這個代碼指的是HTTP狀態碼 (HTTP Status Code),HTTP是爬蟲與伺服器溝通的”語言”,收到請求後,伺服器會用三個數字的代碼告知爬蟲所要求網址的狀態。
- 「2XX」 – 2開頭的代碼代表伺服器能夠處理請求。
- 「3XX」 – 3開頭的代碼重新導向。
- 「4XX」 – 4開頭的代碼代表請求有錯,例如最常見的404網頁不存在。
- 「5XX」 – 5開頭的代碼代表伺服器在處理請求時發生錯誤,例如大家搶買Switch造成家樂福伺服器過載。
Step 3: 頁面處理(Processing)
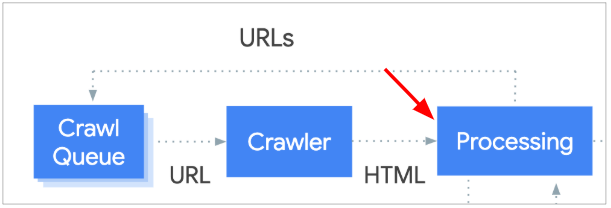
這是抓取階段的最後一個步驟,爬蟲會將成功拜訪(狀況A)伺服器所拿回來的檔案進行處理,在內容中尋找連結,再把它們放入Step 1的檢索序列中,然後如此反覆下去。
這個”處理”的過程又稱作轉譯or渲染(rendering),這個觀念會在下一篇文章再做解釋,但給大家一點預告:「搜尋引擎從伺服器拿回了檔案,但它們會馬上處理嗎? 處理後有保證看得懂嗎?」
SEO意涵: 在檢索的討論範疇內,此步驟最重要的就是「尋找網頁上的連結」。一個網址要被搜尋引擎認定是個連結,就必須被放在<a>標籤裡的href屬性。 使用常見架站平台所架設的網站一般無須擔心這一點,因為正常情況下連結都會使用上述的標準HTML語法來表示。
什麼樣的連結會讓爬蟲看不到?
如果你是位SEO從業人員或網站工程師,那要注意一下這一段,JavaScript讓SEO變得複雜,有些連結雖然一般使用者可以點,但卻會被搜尋引擎無視,下面是幾種常見的情況:
<a href="/good-link">可以爬</a><a href="javascript: changePage('bad-link')">不會爬</a><a onclick="changePage('bad-link')">不會爬</a><span onclick="changePage('bad-link')">不會爬</span><a href="/good-link" onclick="changePage('good-link')">可以爬</a>
SEO在檢索階段能優化些什麼
前面介紹完了搜尋引擎的檢索過程,接下來要講SEO在這個階段能做些什麼事,才讓網站與搜尋引擎保持「友好」關係。其實概念並不難,我們的目標就是要優化爬蟲在檢索自家網站時的體驗,有以下幾個角度可以切入。
確保爬蟲能夠拜訪該被拜訪的網頁
這屬於前一段的Step 2,對於該被拜訪的網頁,爬蟲和伺服器中間的溝通管道必須要暢通。這並不難理解,如果希望網頁出現在搜尋結果,那網頁就不應該用密碼保護、放在防火牆後、或者禁止搜尋引擎拜訪。
確保爬蟲不能拜訪不用被拜訪的網頁
同樣道理,對於沒有要讓搜尋引擎爬的頁面,我們應該用一些方法防止爬蟲拜訪,搜尋引擎即使大如Google,也沒有無限的資源去爬整個網際網路。主動告知爬蟲那些網頁可以不必爬,就是一個「友好」的表現,幫助它們以最有效率的方式找到網站內該被找到的網頁。
確保該被爬的網頁能夠輕易地被發現
這屬於前一段的Step 1,該被拜訪的網頁應該要能夠透過內部連結被發現。想像一個重要的頁面沒有任何連結連近來,Google要怎麼知道它的存在,就算知道了也不會認為他是個重要頁面。
確保伺服器在爬蟲拜訪時給出正確的回應
網址上有東西就說有,沒有東西就說沒有。在一些詭異的伺服器設定中,網址可能傳回來的頁面上顯示該網頁不存在,但同時又給出了網址請求成功的HTTP代碼(2XX)。這情形在SEO中叫做Soft 404 Errors (轉址式404錯誤)。
確保爬蟲的請求可以輕易地送到伺服器
前面有提過轉址,轉址並沒有錯,但轉址太多次就可能是個問題,下面是兩種轉址可能造成的問題。
- Redirect Chain (連續轉址): 爬蟲有個A網址,拜訪後被告知網頁移到了B網址,到了B網址後又被告知移到C網址、D網址、E網址…,轉址發生幾次還好,但次數多了爬蟲可能就會選擇雙手一攤不繼續爬下去。
- Redirect Loop (轉址迴圈): 網址A所在的伺服器告訴爬蟲東西在網頁B,網頁B所在的伺服器又告訴爬蟲東西在網址A,如此無限迴圈下去。
如何防止搜尋引擎爬取?
前面提到,為了讓搜尋引擎能夠更有效率的爬取網站,我們可以用一些方法主動防止搜尋引擎拜訪特定頁面。 再回頭看一次這張圖,能擋住爬蟲的地方是第二步和第三步。

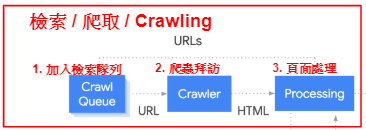
我們沒有辦法在Step 1阻止網址被加入檢索序列, 因為爬蟲可能會從別的地方發現我的網站的連結。
Step 2: 在爬蟲拜訪前給予限制
在爬蟲要拜訪網址時告訴它們這裡不給拜訪。站長可以設置防火牆、用密碼保護、或藉由robots.txt來對爬蟲進行規範。
robots.txt是個文字檔,必須要被放在根目錄的地方,例如本站的robots.txt位置即是 https://www.darrenhuang.com/robots.txt。在這個檔案中我們可以對搜尋引擎的爬蟲進行規範,限制它們那些檔案不可以拜訪(disallow)。
舉例來說,如果robots.txt裡面有一行 Disallow: /secret-weapon,搜尋引擎爬蟲看到檢索序列中的網址內包含/secret-weapon,它們就會掉頭就走。
鑒於這篇文章是基礎,大家只要瞭解可以藉由robots.txt這個檔案限制爬蟲的爬取路徑,詳細的規範和語法可以參考這份Google的文件,如果自認對robots.txt有相當程度的了解可以來挑戰看看數位引擎的robots.txt challenge!
Step 3: 在爬蟲拜訪後給予限制
另外,我們也可以在爬蟲處理頁面時告訴它們「在這裡看到的連結不要放進檢索序列」。
站長們可以用Robots Meta Tag, X-Robots-Tag, 或是連結的rel=”nofollow”屬性來達到這個目的。
- Robots Meta Tag: 在網站的<head>區塊加上
<meta name="robots" content="nofollow" />能防止搜尋引擎將在這個網頁上發現的所有連結加入檢索序列。 - X-Robots-Tag: 在伺服器的回應(server response)中加入
X-Robots-Tag: nofollow能防止搜尋引擎將在這個網頁上發現的所有連結加入檢索序列。 - 連結的rel=”nofollow”屬性: 在連結加上該屬性(例如:
<a href="/dont-crawl" rel="nofollow">不要爬</a>)能防止搜尋引擎將該連結加入檢索序列。
在實務中很少會用到上面這三種方法,如果是自己的網頁不想被爬蟲拜訪通常會在robots.txt就設下限制。nofollow主要和反向連結有較大的關係,但後來因為太容易被錯誤使用,Google已將這個指令改為參考用,並不再嚴格遵守。
若想更進一步了解這些語法的細節,可以參考這幾篇Google文件 – 「連結的rel屬性」、「Robots Meta Tag與X-Robots-Tag」。
如何檢測搜尋引擎有無檢索問題
網頁可以用瀏覽器打開不代表能被爬蟲拜訪。要確認Google爬蟲是否真的可以拜訪的最簡單方式是使用Google站長工具(Search Console)上方的網址檢查工具,它能夠告訴你Google爬蟲在檢索和索引網頁時遇到的問題。

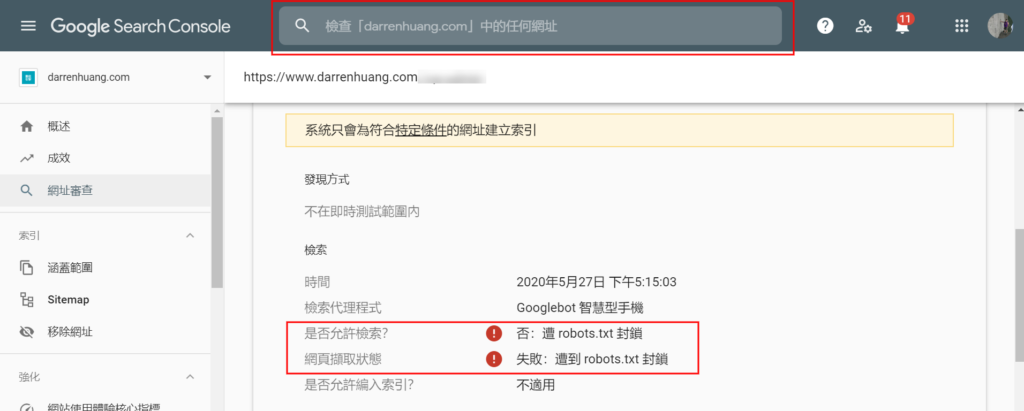
如果在幫客戶或別人的網站偵錯而沒有GSC權限的話,也可以用Google的其他工具,例如移動裝置相容性測試工具(Mobile Friendly Testing Tool)。重點是要用Google的爬蟲來進行測試。

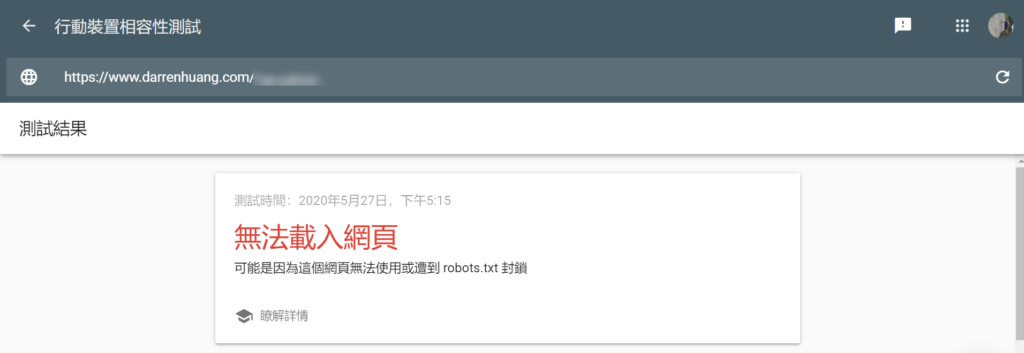
若網頁顯示無法載入(無法檢索)但robots.txt卻沒有什麼問題,很有可能是因為伺服器有防火牆或一些奇怪的設定阻擋了Google爬蟲的請求。伺服器端的問題比較難從外部看出原因,建議直接聯繫主機提供商。
因為「檢索」沒有設定好而出現的悲劇案例
2020年二月有這樣一個新聞,WhatsApp(臉書旗下通訊軟體)的私人群組邀請連結可以在Google搜尋上被找到,包含一些情色和違法的群組,任何人只要都能透過搜尋結果上的連結加入私人群組(每日頭條報導)。
這項悲劇就是因為WhatsApp在檢索階段沒有禁止爬蟲爬取,或是在索引階段沒有禁止搜尋引擎收錄(下個章節再介紹)。私人群組的邀情連結,在爬蟲眼裡也只是個網址,會被放入檢索隊列、爬蟲會去拜訪、當然也可能會在處理後將網頁收錄。

搜尋引擎爬取的常見問題
檢索的觀念在這邊告一段落,到目前為止我們學了「搜尋引擎怎麼檢索網頁?」、「為什麼檢索很重要?」、「SEO該如何優化爬蟲的檢索過程」 …等等,這一段要來講一些常見的問題。
我只有個簡單的網站,有必要懂這麼多嗎?
首先先感謝你看到這邊XD,雖然身為SEO我很想說檢索超級重要,不做好優化會怎樣怎樣,但實際情況是,如果你的網站只是個簡單的部落格或公司網站,很有可能你根本不需要在意搜尋引擎背後運作方式。
前面提到整個網路世界相當大,爬蟲不會花無限的資源在一個網站上。但其實,像Google這樣的搜尋引擎也不是吃素的,它們有自己的機制能夠優化爬蟲的效率,那些連結該爬、那些不該爬、抓取的頻率,諸如此類的問題都不太是一個小網站需要去擔心的。
我可以用robots.txt擋掉私密的頁面嗎
Robots.txt可以擋掉搜尋引擎的爬蟲,但卻擋不掉一般的使用者,在robots.txt上面放上Disallow: /private-page.html只會讓大家好奇這個網址上有什麼不得見人的東西。😉
真的有什麼私密的東西要放在網路上,最好的辦法還是用密碼保護!
電商網站在檢索階段的常見問題
電商網站通常有所謂的層面導覽(Faceted Navigation),舉例來說一個電商網站的男裝類別頁面,左側有個區塊可以將產品根據條件篩選 – 「尺寸」、「品牌」、「顏色」…等等。每加一個條件,網址就會變化,像下面這樣:
/mens-clothing男裝/mens-clothing?size=XLXL男裝/mens-clothing?size=XL&brand=nikeXL的Nike男裝/mens-clothing?size=XL&brand=nike&color=redXL的紅色的Nike男裝
上面這個例子只有三個篩選條件(size, brand, color),但現實生活中的電商平台會有更多的篩選條件,試想每個條件都有多個選項,然後有些篩選條件可以複選或不選,甚至?後的出現順序不同 (例如?brand=nike&size=XL vs ?size=XL&brand=nike )……看到這邊你可能知道我要說什麼了,沒錯,排列組合下來光一個男裝類就會產生大量的網址,這些網址在爬蟲眼裡每一個都是「獨立」的網址,外加上面的內容品質不高!!
我是不是每發布一篇文章就要用站長工具提交給Google知道,讓它盡快被排進檢索隊列
爬蟲發現網址有主要透過三種方式,主動提交只是其中一個,不做這個動作Google還是能從其他方法看到這個連結。另外,提交的確可以讓網頁快速被抓取和收錄沒有錯,但和排名是沒有任何關係的。
通常一個健康的網站,就算不提交網址,Google也能在網頁發布後一小段時間內發現,可以不用特別去提交。但如果你發現文章發布後都要好幾天才會被收錄,那可以試試看使用提交工具,但有這個現象的話更重要的是去檢查網站有沒有什麼其他問題。
網址的格式會影響搜尋引擎檢索嗎?
不會。一個網頁的網址不管設成https://example.com/seo-friendly或https://example.com/?p=3828482都只是個網址。很醜的網址並不會對爬蟲在檢索的過程造成影響。其他爭議像網址是不是.html結尾、有沒有用中文、使用連字號「-」還是底線「_」,其實都沒有關係,網址就是網址,不會影響到搜尋引擎檢索的。至於用了漂漂亮亮的網址和排名有沒有關係就不是這篇的討論範圍了!
小知識: 其實前面這段敘述有一點不太正確,HTTP狀態碼有一個414 URI Too Long的錯誤,代表網址太長了伺服器或爬蟲不想處理。但這個限制可以高達2000個字元,所以不是個正常網站需要去擔心的問題。(Stackoverflow討論)
還有什麼關於「檢索」的問題或疑惑,到這邊還沒有被回答到或不夠清楚嗎,歡迎留言讓我知道,我會在留言回答或是編輯到上面的常見問題區! 這篇文章本意就是要寫給新手知道,所以有不懂的地方就是我的問題,把你的奇怪問題都拋出來吧!
結語
關於搜尋引擎的「檢索」過程介紹就在這邊告一段落,感謝一路看到這邊的你,之後有時間會再把另外兩個步驟「轉譯」和「索引」也寫成文章。「數位引擎」是我閒暇之餘經營的臉書粉絲頁,下面這張圖是以前曾分享過的一個冷知識,和這篇的主題有點關聯,希望大家現在有辦法get到這個幽默!
謝謝 Darren 的分享!
對 SEO 初學者很友善的內容
這是我想聽到的! Thanks~
相當棒的介紹,搭配粉專的小測驗更容易釐清觀念。
感謝Danny!! 粉專的測驗是指robots.txt challenge嗎,之後會考慮放到這邊來用個比較好的方式呈現,臉書相簿實在不是個好玩遊戲的地方XD
謝謝分享,身為一個小小的電商人,這篇文章非常深入淺出。
同時也提醒內容似乎有錯字:
「若網頁顯示無法載入(無法檢索)但robots.txt卻沒有什麼問題,很有可能是因為伺服器有防火牆或一些奇怪的設定阻擋了Google爬蟲的請求。伺服器端的問題比較難蟲外部看出原因,建議直接聯繫主機提供商。」
服器端的問題比較難*蟲*外部看出原因→從。
Thanks Hung! 這篇文章用了太多”蟲”這個字,搞得有點ㄔㄘ不分了XD,已修改~
Darren哥您好,
小弟最近開始經營blog,有些seo的問題
請問能跟您請教嗎?
Looking forward to your reply, thanks
可以寄email來,問題盡量詳細,我有空會回答~
謝謝 Darren 分享實用的訊息
在整理GSC 中的error message 後看到這篇文章更有感。
太好了! 很高興寫這麼久的文章真的有幫助到人!
請問怎麼知道爬蟲crawl frequency?
Google Search Console中有提供一個Crawl Stats Report,告訴你Googlebot與網站的互動情形(來了幾次、下載多少檔案、平均回應時間、googlebot種類…等等)
如果要更詳細地知道每個網頁的crawl frequency,需要透過自己的伺服器log file來做分析~